
Talend offers a software for cleaning and formatting data. The software is very
intuitive. I’m using free Desktop version, so I can’t get wild with data
sources. There are only two options: Excel and CSV.
Surprisingly
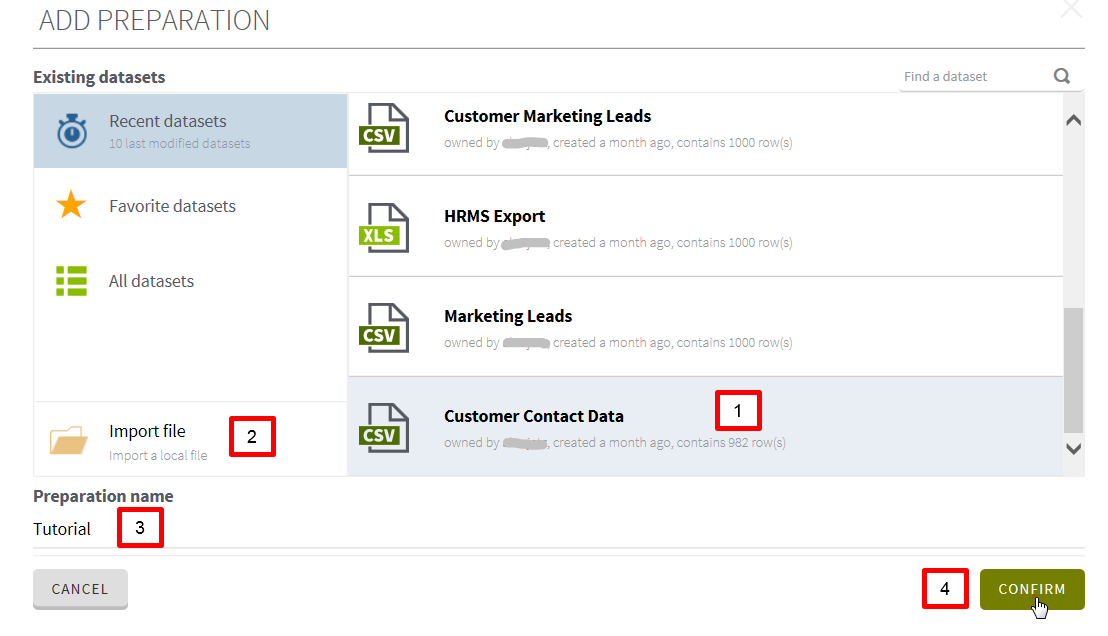
let’s import the dataset at the beginning…
Talend
includes some datasets to play with.

I’ll use Customer Contact Data.
….but you are free to use your own
dataset.
You can give a nice easy name to
your preparation.
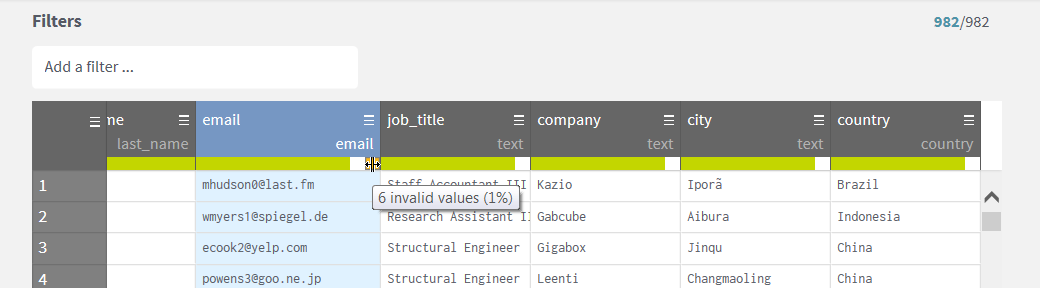
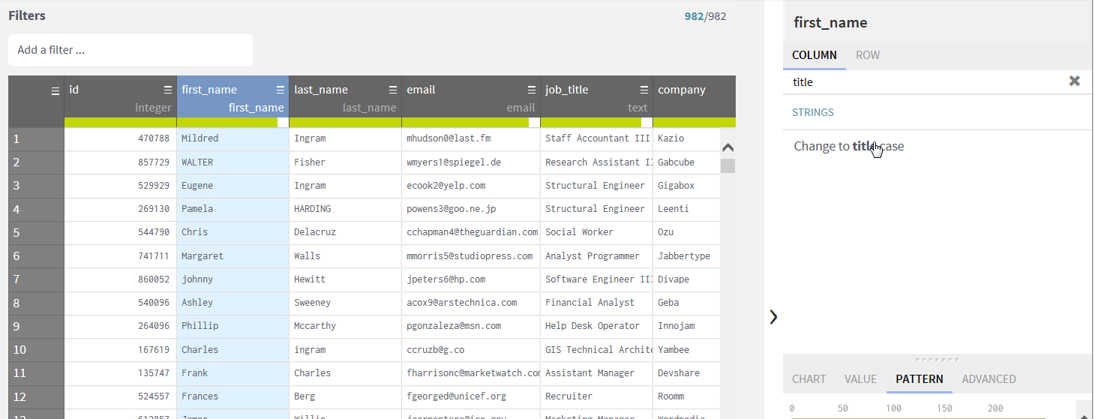
I see that
some emails are not valid, so I select the column email by clicking on the
header. My dataset has only 982 rows.

I don’t
have any superpowers, I knew that some data doesn’t match the cell format as
under each column is a Data Quality bar.
Green –
data matches the format
White –
there is nothing (NULLs)
Orange – the cells include data but it doesn't match the format.

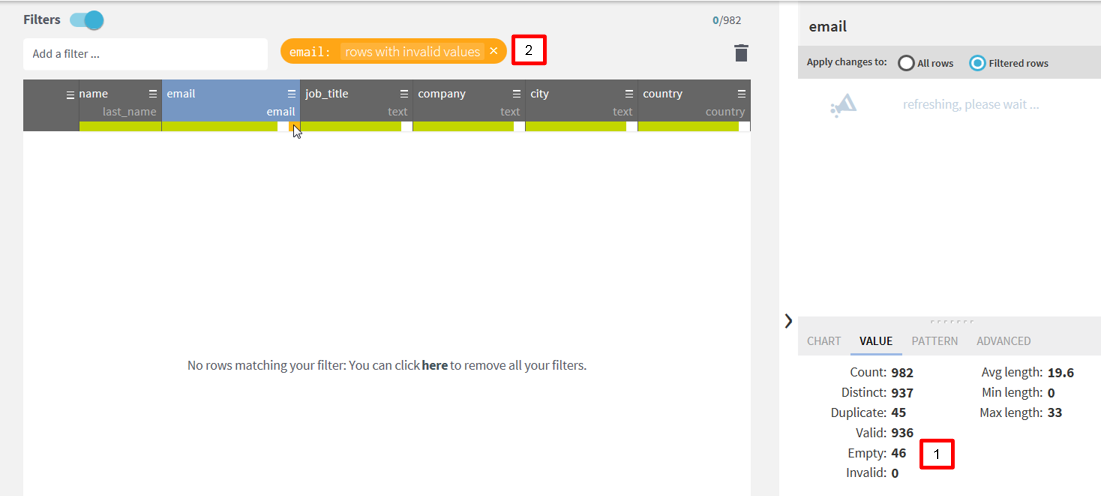
Some information
about quality of the selected column is also present in Data Profiling Tab.

There is
possibility to delete the cells with invalid values or even delete the entire
rows consisting problematic cells. Before using such drastic steps, it is a
must to investigate the details.

There was
comma instead of dot in an email, so I’ve corrected that manually by double
clicking the cell, I’ve made a tick next to apply to all cells with this value.
It’s useful when a value appears multiple times. Here it plays no role lol.

After correcting the comma I’ve only 5 incorrect values (at the beginning of the process I had 6!) and I will clear the cells as there is
no chance to guess the correct addresses.

Number of
nulls has increased. To delete the orange filter click at the cross.
I see more
problems, there is an empty space after Frank.

What if Frank with his empty space was in the row number 900? Should I devote an
hour to search for Frank? There are other places, where I can find him
easier.
I’m
checking Patterns in Data Profiling tab…
No, he is
not here.
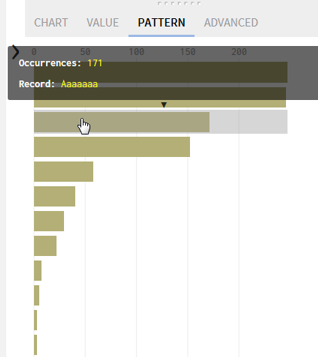
Frank, you
are surrounded

I’ve
discovered more problems, there are two names starting with a small letter.
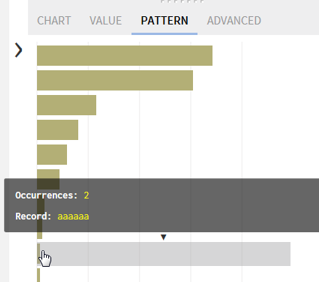
The problem
with empty spaces is solved by selecting function Remove trailing and leading
characters (whitespaces) and the cure for the second problem is Change to title
case.

Mask data
function gives possibility to hide some sensitive information.

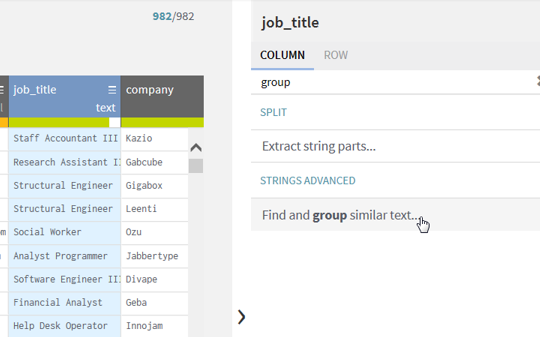
The column
job_title consists too many details about positions, Find and group similar
text function is a good choice in this situation.
Talend can
advise but the final decision belongs to you, if you don’t want to accept
entire group suggested by Talend, you have to delete a tick in the first column.
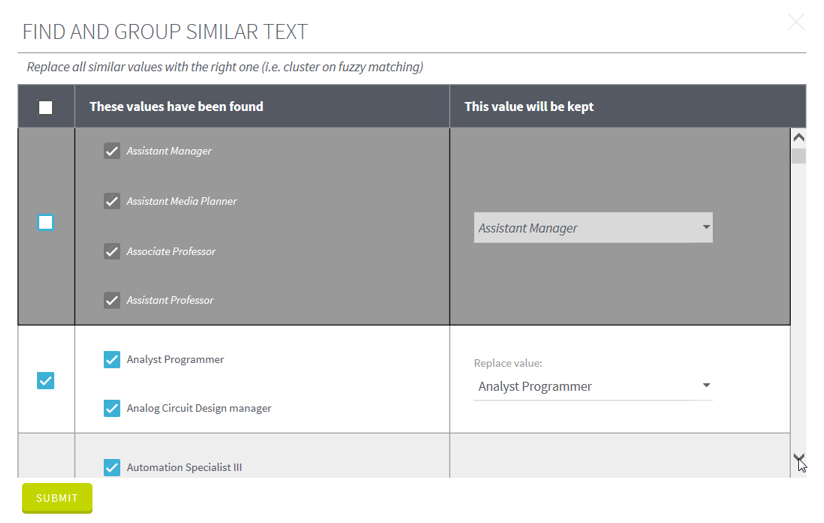
If you want
to keep a suggested group but delete some members from it, untick members
in the second column.
To change
names of suggested groups double click them.

Talend
automatically saves all activities in this side bar on the left.
Function
order can be changed by pulling the functions up or down. You can delete steps by clicking on the rubbish bin
next to an unwanted function.

Exporting button is in the right upper corner. All the changes don't affect data in your data source, you have to export data to be able to analyse your new clean dataset.

No comments:
Post a Comment